


Artificial intelligence (AI) is a fascinating field of technology, that is promising to change the world. For decades, artificial intelligence has been just a part of science fiction. Not anymore. Today, we find AI systems assigned to certain tasks everywhere around us, and perhaps we are not far from an AI that thinks as a human does, or better. The driving force behind this is called machine learning. Let's see how it works.
Unblock any international website, browse anonymously, and download movies and Mp3 with complete safety with CyberGhost, just for $2.75 per month:

Are computers smart devices?
Although we may consider our PCs, smartphones, and tablets to be "smart" devices, in reality, we know that they do not "think" the way a human does.
Every device is based on one or more applications that some developer has created. Every application has exactly the capabilities that its code gives it. Nothing more, nothing less. Whatever has not been accounted for by the code, leads to an error.

In simple applications, the programmer can foresee all the possible actions of the user, so that they can incorporate a suitable reaction in the script.
However, the more complex an application, the harder it gets to account for every possible outcome. This is the reason why every operation system - by default, the most complicated application in every system - has countless security holes.
Trying to build something so complex that can respond to any challenge like a human, would simply be impossible using conventional programming methods.
What is machine learning
Let's take a moment to think about how human thinking and learning works. Unfortunately, we can't have someone program information straight into our heads. At least not yet.
How we learn, in essence, is by observing our environment for information, through which we reach certain conclusions.
Machine learning is based on similar logic. Instead of trying to program every possible parameter, we have created algorithms that manipulate a set of information. Based on the input -that is, the data- the algorithm then builds its own logic, adjusting its function.
For instance, let's take the question that involves the following pairs of numbers:
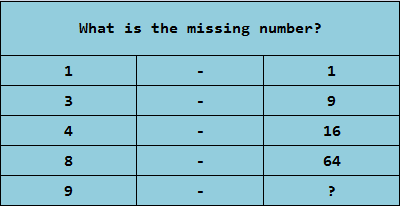
A human can quickly conclude that the next number is 81, as it's apparent that the numbers in the right column are the squares of the numbers in the left one. After examining the data, we can see a relation between them.
A conventional program, specifically written to solve this problem, would simply begin testing every possible solution in place of the question mark, starting from 1 and moving upwards.
When reaching 81, we should have programmed a confirmation that this is the right answer. Otherwise, the program would keep counting numbers until it runs out of memory.
Of course, based on this example, this program would find the answer faster than a human, because a computer can carry out billions of computations per second.
For any different problem, however, our previous program would be useless; we would have to write a new one. And for problems with not so mathematically specific solutions, it is impossible to find a solution just by trying every single possibility.
Through machine learning, we aim at a computer that can work more like humans do. We want our algorithms to be capable of learning empirically, based on the observations - samples we provide.
As we will see, machine learning allows algorithms to improve their performance with time. The more available samples we have, the more efficient the algorithm becomes.
Where is machine learning used
Everything we have mentioned so far is not just theoretical. As you read these lines, artificial intelligence is everywhere around us, in the form of algorithms.
We should stress out here that what we are referring to is not a complete AI, which thinks entirely like a human. We are talking about specialized AI applications for certain tasks.
For instance, most of us have used a search engine on the internet, at least once.
The results we see on our screen were not manually chosen by some Google employee. Special algorithms attempt to understand what we are looking for and show us the most related results.
Similarly, it is machines that decide what we'll be getting on our Facebook feed, and in what order and in what order, whether our transaction at the ATM is valid, what our autocomplete Google search results will look like, etc.
All these functions are spectacularly improved using machine learning. So, let's see how we have managed to create algorithms that learn on their own.
Evolution of algorithms
Once, scientists used to build algorithms the obvious way: by giving them commands, just as humans understand them.
Yet, we gradually started facing problems so complex that giving them to a machine in the form of commands would be next to impossible.
Showing suggestions on YouTube, among thousands of available videos, or discovering invalid transactions, among millions taking place each second, are examples of such problems.
Machines with the use of algorithms give us answers to these questions. Answers which, quite often, are inaccurate or imperfect.
Still, though, these answers are much better than the ones a human would give for the same question. It would take years for a team of even a thousand people to process the amount of data produced in one second worldwide.

How machine learning works
Before we attempt to explain how machine learning works, we have to note that all we know is just the basic rules.
A big reason behind this is the fact that the exact nature of the algorithms each business uses is a valuable trade secret.

There is a reason why Google is that much more popular than, say, Bing. A Google search will return better results. Google's search algorithms are vastly superior to its competitors'.
We can safely assume that Google implements some machine learning method for its algorithms. However, the details are highly classified for anyone outside their development environment.
A simple machine learning example
Developing algorithms using machine learning is based on neural networks and, in general, on highly complex mathematical concepts. We would need years of studying to thoroughly understand even a small portion of these.
What we can do is see how the whole thing works with a simple example. Now, let's say we want to build a bot, an algorithm that recognizes what's inside a picture.

Which photo has a tree and which has a ship? That's a question that a two-year-old can answer, but it is too hard for us to program a computer that will always give the correct answer.
Our brain instantly knows what an image depicts within just a moment of laying our eyes on it. We may comprehend how the cerebral lobes or the nerve synapses work, yet the way the brain functions as a whole remains a mystery.
We can use words to explain why the first image is a tree (it has a trunk, leaves, roots) and the second a ship (it has sails, masts). But computers don't know what these words mean. They don't understand anything.
Understanding is still exclusive to our brains.
Building algorithms and teaching them
Since we don't know how exactly the brain can comprehend the content of a picture, we cannot directly program an algorithm that does the same.
What we actually do is build two bot algorithms. One to build its own bot algorithms, and one to teach them.
Such algorithms are much less complicated. Thus, a clever developer can build them.

The builder bot will create a number of bots, with the purpose of checking pictures and answering whether they contain a ship or a tree.
These bots are, of course, not identical with each other; there will be small differences in the way they work. Otherwise, the whole building process would be pointless. These differences are formed almost at random.
This does not particularly concern us as, later, with the help of machine learning, they will start getting shaped in the right direction.
Next, the new bots are sent to the teacher bot, to train on how to recognize trees and ships.
Naturally, neither the teacher algorithm can discern whether a picture shows a tree or a ship. If it could, then our problem would be solved, and we wouldn’t need the rest of the procedure.
What we do is feed the teaching algorithm with as many pictures as possible. Pictures with either a tree or a ship.

Along with each picture, we also provide the right answer, whether it’s a tree or a ship. This way, although the teacher-bot cannot tell apart trees from ships, it knows which answers are right and wrong.
Next step, the test begins. Every bot the builder-bot has created goes to the teacher-bot. Teacher-bot shows a picture, and the bot has to answer whether it’s a ship or a tree.
In this first generation, most of the bots we built are going to fail.

It’s essentially a matter of luck whether a bot will find the correct answer, based on the random differences in its programming, compared to the other bots.
Teacher-bot automatically separates the bots that answered correctly. Those that failed are useless and get destroyed.

Now, the builder-algorithm takes the bots that passed the test and makes copies of them, subsequently applying minor changes to their programming.
Then, the stages we just described repeat: teacher-bot repeats the tests on the new bots, builder-bot keeps those who did better and prepares new versions, etc.
Iterations
Perhaps this whole method seems pointless, but it actually bears fruits.
It is similar to the way the evolution of species works in nature. Based on random mutations, the most capable of a species reproduce in greater numbers and, after enough generations, the result barely looks anything like the original.
In each iteration, the building algorithm keeps only the best bots, while the ones sent to the teaching algorithm are countless.
The same goes for the tests, which consist of millions of answered questions to be examined. The more data system creators provide for examination, the better it is for machine learning.
With every new generation of bots, the code that initially allowed them to just get the right answers at random keeps improving. After countless iterations, we are gradually getting machines that do pretty well at distinguishing trees from ships.

Since the whole process is automated, no one knows how exactly the end algorithm – the one that excels at telling trees from ships – is made.
With all the repeated changes and random progress, it has eventually become very complex. And since machines wrote the code instead of humans, even if we examine it, we won’t be able to figure out exactly how it works.
This brings us back to the human brain. We may understand certain parts of it, but not how it works as a whole.

Data collection
It is worth noting that machine learning is a constant process, and there is no moment when we could consider it to be complete.
An algorithm that, in theory, is excellent at distinguishing pictures of trees and ships will still have problems once given, say, a video, even if the task is exactly the same; simply understanding whether a ship or a tree is being depicted.

This leads to the need for continuously training our bots.
Provided that we have no alternative, our only choice is to keep feeding the teaching machines with tests, including increasingly harder questions.
But where could one possibly find so much material?
Hmmm…
Apparently, that is why so many companies have become obsessed with data collection and the concept of “Big Data.”
The more data we have, the more educational material there is available to improve our algorithms. And, as material with enough diversity is scarce, its value grows.
Our involuntary participation in machine learning
When we get the typical “Are you a human?” test on a website, we are not just proving that we are indeed human.
At the same time, we are contributing to building tests for algorithms that learn how to recognize text, count, tell apart trees from ships, or horses from humans.

We might have noticed how impressively often these quizzes include roads, vehicles, or road signs lately.
This probably means that they are related to training algorithms that will soon replace us in the driver’s seat.
Alas, there is another kind of test in which we, as a human, take part in a different way: being the subject under review.
A common example is YouTube’s algorithms. One of their purposes is to suggest videos, according to each person’s tastes, so that we keep browsing on the website for as long as possible.
How is this done? Simply, a teaching algorithm assigns to student-bots a number of users to oversee. The student-bots, in turn, do their best at suggesting the appropriate videos to each of their users.
The algorithms that retain their users for the longer period of time would constitute the best among their generation. After millions of repeats, machine learning will lead us to an algorithm that is extremely competent at capturing and keeping the user's interest.
Once again, we don’t know exactly how the algorithm that gives us the suggested videos works. The only thing we know is how we can design its machine learning, and what data we used for its training.
Machine learning today
We realize that machine learning is everywhere around us. In most aspects of our everyday life, there already are algorithms using machine learning.
Even where they are not, the potential use of machine learning can be helpful. An example is the news of an innovative machine learning application in the otherwise innocuous field of (legal) pornography.
Pornhub, the highly popular “video streaming” website, is attempting to put an end to all the inaccurate descriptions of videos we had to endure till now.

To achieve this, they combine AI with machine learning. With a procedure similar to the one described earlier, their algorithm is being fed with faces, positions, “techniques,” etc.
The next step is to proceed to catalog their videos, describing the types of “act” they contain, the actors, and deleting any duplicates.
Now, if we want to get a better taste of how machine learning works, Teachable Machine gives us the opportunity to do so.
Here we can teach a machine by giving it the samples it needs. As a result, we can take a look at the process through which it learns things.
What do you think about machine learning?
With machines now learning on their own, we increasingly use (or get used by) tools with functions virtually unknown to us.
What's certain is that, inevitably, we have to get used to this idea. Sooner or later, machine learning will be a part of every aspect of our life. Whether that’s a good or bad thing is left for the reader to decide.
Feel free to share your thoughts on this prospect with us in the comments. Is the future filled with positive changes, or are we about to experience a new age of the machines?
Support PCsteps
Do you want to support PCsteps, so we can post high quality articles throughout the week?
You can like our Facebook page, share this post with your friends, and select our affiliate links for your purchases on Amazon.com or Newegg.
If you prefer your purchases from China, we are affiliated with the largest international e-shops:

Leave a Reply